
Note: This is an article I wrote for the official Booster Framework dev.to blog. Note 2: I recommend you to use light mode (top right button to change it) for this concrete article. Long time ago, when I wrote it, I messed up with the colors. I will change it if I find some spare time.
It’s been a while since we first started our way into event-sourcing and, from our experience, we really think that there is still space to dig into what event sourcing is and why it’s useful for modern backend applications. But first…
What’s event-sourcing?
Event-sourcing is a collection of patterns that introduces a new way of thinking, where domain events are the source of truth (domain referring to domain-driven design). We need to fulfill the following contract:
- The event store persists the full history of domain events. For example:
UserRegistered UserChangedPassword UserPublishedAnArticle
- Domain events must be chronologically ordered
- Domain events are immutable
Given #1 and #2, we can actually replay domain events. That is, reconstructing the state of your application by running the full history of domain events, which can give you the chance to reconstruct the current state of your system and go back to a specific point in time, allowing the following:
- Easily find bugs from the system and reconstruct those bugs in different environments.
- Deploy different versions of your backend for testing purposes.
- Recover from errors by replaying events from a specific point in your system.
Specifically for microservice architectures, there is one case when this comes in handy: Imagine adding a new service, meaning a new read model (local DB) needs to be created. For this purpose, we need to reconstruct the current state of domain models by replaying domain events from the Event Storage. This operation becomes easier when adding snapshotting to the formula.
Snapshotting for event replaying
Snapshots represent the current state of an entity (or aggregate) at a specific time. Snapshots can be configured to be done whenever you want. For example, every X events, X days, or when something special happens in your system.
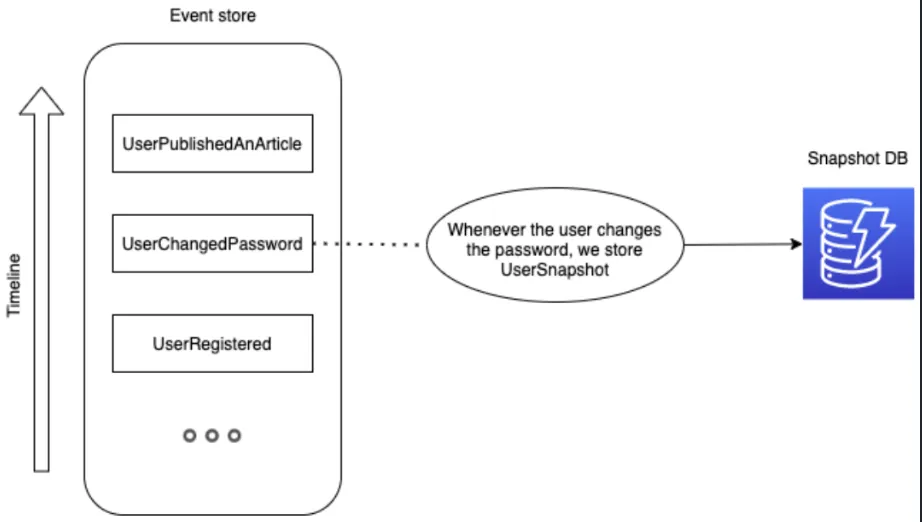
Replaying events then becomes easier, because you can start rebuilding your service from a specific point of your events’ timeline, and then run all further events from that point. Check the example below.
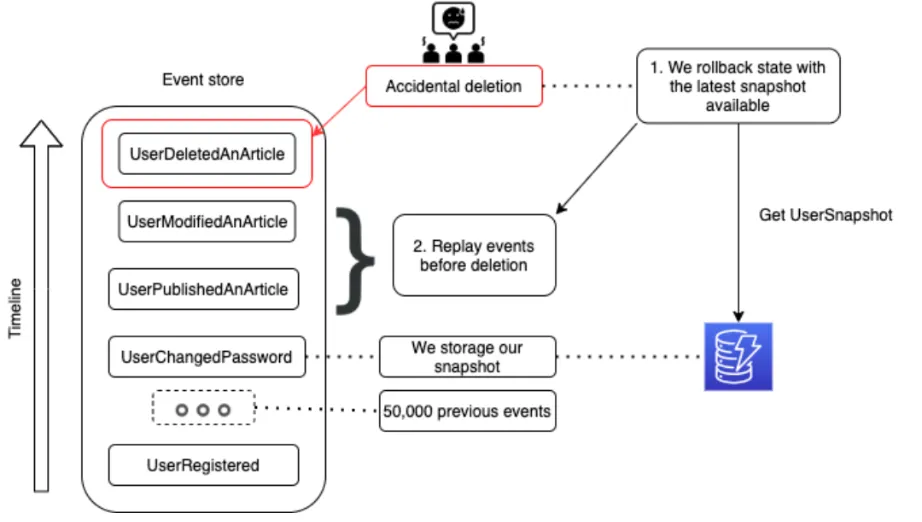
As you can see, you don’t have to go back to the first UserRegistered event and run all events, but instead, you just take advantage of snapshotting and rollback the User state just before deleting the article.
Not everything is shiny
Definitely, event sourcing advantages were the ones that motivated us to enter this field, but along the way, we found that things weren’t as easy as the theory says:
- With high traffic, what would happen if your application goes down? How are you going to recover from the previous failed events plus keep receiving the new ones?
- How do you handle side effects? For example, when replaying events imagine that one of the events calls your email service. In that case, we should check that the email was previously sent, or otherwise while we replay the events, the user could end up with a lot of repeated emails.
- When should you store a snapshot? Snapshotting depends a lot on the business needs, so we should be open to leave this as configurable as possible, or just generalize it and snapshot every X events.
- Is it better to store snapshots synchronously or asynchronously? Synchronous snapshot persistence could happen if you’re not worried about persistence latency.
- How do you handle new events coming while replaying events?
- How are you going to manage GDPR? As events must be immutable, theoretically you can’t delete events even if they contain personal data.
These problems can be probably solved by adding more control parameters to your events, adding additional checks (to avoid side effects for example), or having a high available queue system like Kafka/RabbitMQ in the middle of your store and your database (for events queuing and system recovery).
Although, what we’ve missed these years is an event-sourcing standard implementation, where the developer doesn’t have to think about the big complexity it has to develop the majority of useful use cases. That’s what we’ve been trying to do with Booster Framework, and we are really excited about what we’ve currently achieved.